到底什么是hash
hash算法的概念
Hash:
- 一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
- 这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
例子:
你很想学太极拳,听说学校有个叫张三丰的人打得特别好,于是你到学校学生处找人,
学生处的工作人员可能会拿出学生名单,一个一个的查找,最终告诉你,学校没这个人,
并说张三丰几百年前就已经在武当山作古了。
可如果你找对了人,比如在操场上找那些爱运动的同学,人家会告诉你,"哦,你找张三丰呀,
有有有,我带你去。于是他把你带到了体育馆内,并告诉你,那个教大家打太极的小伙子就是张三丰',
原来"张三丰.是因为他太极拳打得好而得到的外号。学生处的老师找张三丰,那就是顺序表查找,
依赖的是姓名关键字的比较。而通过爱好运动的同学询问时,没有遍历,没有比较,
就凭他们"欲找太极'张三丰',必在体育馆当中"的经验,直接告诉你位置。
HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,通俗的说hash就是找到一种数据内容和数据存放地址之间的映射关系。
hash表
Hash表也称散列表,也有直接译作哈希表,Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。
Hash表的设计思想
对于一般的线性表,比如链表,如果要存储联系人信息:
| 张三 | 13980593357 |
| 李四 | 15828662334 |
| 王五 | 13409821234 |
| 张帅 | 13890583472 |
那么可能会设计一个结构体包含姓名,手机号码这些信息,然后把4个联系人的信息存到一张链表中。
查找数据:
当要查找”李四 15828662334“这条记录是否在这张链表中或者想要得到李四的手机号码时,可能会从链表的头结点开始遍历,依次将每个结点中的姓名同”李四“进行比较,直到查找成功或者失败为止,这种做法的时间复杂度为O(n)。
假设能够通过”李四“这个信息直接获取到该记录在表中的存储位置,就能省掉中间关键字比较的这个环节,复杂度直接降到O(1)。Hash表就能够达到这样的效果。
原理:Hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置.
通常情况下,这种映射关系称作为Hash函数,而通过Hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为Hash地址.
比如上述例子中,假如联系人信息采用Hash表存储,则当想要找到“李四”的信息时,直接根据“李四”和Hash函数计算出Hash地址即可
hash函数
hash函数就是把任意长的输入字符串变化成固定长的输出字符串的一种函数。输出字符串的长度称为hash函数的位数。
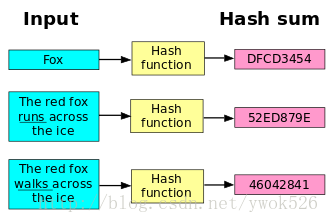
一句话:散列(Hashing)通过散列函数将要检索的项与索引(散列,散列值)关联起来,生成一种便于搜索的数据结构(散列表)。

散列函数的性质:
同一函数的散列值不相同,那么其原始输入也不相同,上图中k1,k3和k4。(确定性)
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是不相同的,上图中的k2,k5这种情况称为“哈希碰撞”。(不确定性)
hash函数的构造准则:简单、均匀
1、 散列函数的计算简单,快速;
2、 散列函数能将关键字集合K均匀地分布在地址集{0,1,…,m-1}上,使冲突最小。
对象的获取
思考:
java虚拟机是如何去内存里面获取到我们想要的对象呢?

问题:
站在JAVA虚拟机的角度,在内存里面有好多好多个对象,这里用椭圆来代表一个个对象。那么对于JAVA虚拟机来说,它运行的时候需要找到这些对象的地址,这些对象的地址怎么找呢?
解析:
JAVA虚拟机会用一张表记录每一个对象在什么位置上,而这张表一般是用哈希编码来记录,每一个对象都有自己独一无二的哈希编码,根据这个编码就可以找到相关的对象,也就是说,根据这个编码你可以独一无二地确定这个对象,并且可以非常快地确定这个对象所在的位置,可以简单这么理解哈希编码的作用。
hashcode方法
在object类中,hashcode()方法是本地方法,返回的是对象的地址值。

JAVA代码:
从这个结果中我们可以看到。obj1和obj2的hashcode编码不相等,obj2和obj3的hashcode编码相等。我们可以这样说,obj2和obj3在内存里面引用的是同一个对象。
equals方法
在object类中有一个方法叫equals(),用于判读两个对象是否相等。
java代码:
API Object类中源代码:
也就是当我们写了一个自己的class,然后用class new了两个对象,如果在这两个对象上用equals时,此时比较的两个引用是不是一样,也就是他们的物理地址是不是一样,如果不一样的话,就会返回false.
|
|
我们实际用的时候,往往不是希望比较两个对象的物理地址是不是一样,而比较两个对象的属性等东西是不是一样,所以Object提供的方法往往不能满足我们要求。
这就需要我们覆盖Object的equals方法。
如果要覆盖Object的equals的方法,一定要满足以下几个等价关系:
- 自反性,对于任何非null的引用值x,x.equals(x)必须反回true
- 对称性,对于任何非null的引用值x,y,当且仅当y.equals(x)返回true时,x.equals(y),才返回true.
- 传递性,对于任何非null的引用值x,y,z,如果x.equals(y)返回true,并且y.equals(z)返回ture,那
么x.equals(z)也必须返回true. - 一致性,对于任何非null的引用值x,y,只要equals比较操作的两个对象中所用的信息没有被修改,多次
调用x.equals(y)就会一致的返回true,或者一致的返回false.
5.对于任何的非null的值x,x.equals(null),必须返回false .
在Student类里面重写了父类的equals方法:
|
|
HashSet和HashMap
HashMap的工作原理
equals:是否同一个对象实例。注意,是“实例”。比如String s = new String(“test”); s.equals(s), 这就是同一个对象实例的比较;
等号(==):对比对象实例的内存地址(也即对象实例的ID),来判断是否是同一对象实例;又可以说是判断对象实例是否物理相等;
Hashcode:我觉得可以这样理解:并不是对象的内存地址,而是利用hash算法,对对象实例的一种描述符(或者说对象存储位置的hash算法映射)——对象实例的哈希码。
HashMap的数据结构是基于数组和链表的。(以数组存储元素,如有hash相同的元素,在数组结构中,创建链表结构,再把hash相同的元素放到链表的下一个节点).
hashMap的结构类似这样
|
|
假设没有hashCode=1的元素加入,但是有两个hashCode=0的数据,它的结构就变成这样
|
|
put和get都首先会调用hashcode方法,去查找相关的key,当有冲突时,再调用equals(这也是为什么刚开始就重温hashcode和equals的原因)!
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
HashSet排除重复原理
Java中的set是一个不包含重复元素的集合,确切地说,是不包含e1.equals(e2)的元素对。Set中允许添加null。Set不能保证集合里元素的顺序。
在往set中添加元素时,如果指定元素不存在,则添加成功。也就是说,如果set中不存在(e\==null ? e1\==null : e.queals(e1))的元素e1,则e1能添加到set中。
下面以set的一个实现类HashSet为例,简单介绍一下set不重复实现的原理:
|
|
|
|
通过结果来分析,我们看到a和b返回true那是因为String类重写了equals方法,但是打印集合里面的数据,却只输出了一个A,c和d都输出了。那我们就要思考,难道set集合排除重复跟equals方法有关吗?,接下来继续进行测试。
|
|
这次的equals返回值都为true,但是set的size还是3。
通过这个结果我们可以看出,重写了equals方法可以判断两个对象的值相等。所以第二个判断输出了true,但是并没有影响set集合里面的数据。
继续修改代码:
如果只重写hashcode方法,set集合里面的数据还是没有变化。
继续来测试:
现在我们获取到的集合长度为2,已经将重复的数据进行排除了。